Lowest Common Ancestor (LCA) - ফারাক-কোল্টন ও বেন্ডার অ্যালগরিদম#
ধরি $G$ একটি ট্রি। প্রতিটি $(u, v)$ আকারের কুয়েরির জন্য আমরা $u$ এবং $v$ নোডের LCA বের করতে চাই, অর্থাৎ আমরা এমন একটি নোড $w$ খুঁজতে চাই যেটি $u$ থেকে রুট নোড পর্যন্ত পাথে অবস্থিত, $v$ থেকে রুট নোড পর্যন্ত পাথেও অবস্থিত, এবং একাধিক এরকম নোড থাকলে আমরা রুট নোড থেকে সবচেয়ে দূরেরটি বেছে নিই। অন্যভাবে বলতে গেলে, কাঙ্ক্ষিত নোড $w$ হলো $u$ এবং $v$-এর সবচেয়ে নিচের অ্যানসেস্টর। বিশেষত, যদি $u$ হয় $v$-এর অ্যানসেস্টর, তাহলে $u$ হলো তাদের LCA।
এই আর্টিকেলে বর্ণিত অ্যালগরিদমটি ফারাক-কোল্টন এবং বেন্ডার কর্তৃক তৈরি। এটি অ্যাসিম্পটটিক্যালি অপটিমাল।
অ্যালগরিদম#
আমরা LCA সমস্যা থেকে RMQ সমস্যায় ক্লাসিক্যাল রিডাকশন ব্যবহার করি। আমরা DFS দিয়ে ট্রি-র সব নোড ট্রাভার্স করি এবং সব ভিজিট করা নোড ও তাদের উচ্চতার একটি অ্যারে রাখি। $u$ এবং $v$ দুটি নোডের LCA হলো ট্যুরে $u$ এবং $v$-এর উপস্থিতির মধ্যবর্তী সবচেয়ে কম উচ্চতার নোড।
নিচের ছবিতে তুমি একটি গ্রাফের সম্ভাব্য অয়লার-ট্যুর দেখতে পারবে এবং নিচের তালিকায় ভিজিট করা নোডগুলো ও তাদের উচ্চতা দেখতে পারবে।
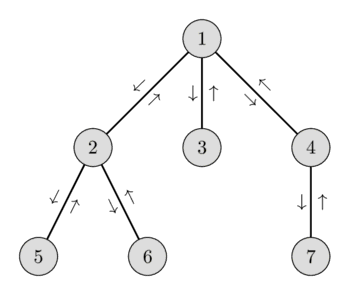
তুমি এই রিডাকশন সম্পর্কে আরো পড়তে পারো LCA আর্টিকেলে। ঐ আর্টিকেলে একটি রেঞ্জের মিনিমাম sqrt-ডিকম্পোজিশন দিয়ে $O(\sqrt{N})$-এ অথবা সেগমেন্ট ট্রি দিয়ে $O(\log N)$-এ বের করা হয়েছিল। এই আর্টিকেলে আমরা দেখব কীভাবে দেওয়া RMQ গুলো $O(1)$ সময়ে সমাধান করা যায়, প্রিপ্রসেসিং-এ শুধু $O(N)$ সময় নিয়ে।
লক্ষ্য কর যে রিডিউসড RMQ সমস্যাটি খুবই বিশেষ: অ্যারের যেকোনো দুটি পাশাপাশি উপাদান ঠিক এক দ্বারা পার্থক্য হয় (যেহেতু অ্যারের উপাদানগুলো ট্রাভার্সালের ক্রমে ভিজিট করা নোডগুলোর উচ্চতা ছাড়া আর কিছু নয়, এবং আমরা হয় একটি ডিসেন্ডেন্টে যাই, সেক্ষেত্রে পরবর্তী উপাদান এক বেশি, অথবা অ্যানসেস্টরে ফিরে যাই, সেক্ষেত্রে পরবর্তী উপাদান এক কম)। ফারাক-কোল্টন ও বেন্ডার অ্যালগরিদম ঠিক এই বিশেষায়িত RMQ সমস্যার সমাধান বর্ণনা করে।
ধরি $A$ হলো সেই অ্যারে যার উপর আমরা RMQ করতে চাই। এবং $N$ হলো $A$-র আকার।
একটি সহজ ডেটা স্ট্রাকচার আছে যা $O(N \log N)$ প্রিপ্রসেসিং এবং প্রতিটি কুয়েরিতে $O(1)$ দিয়ে RMQ সমাধান করতে পারে: স্পার্স টেবিল। আমরা একটি টেবিল $T$ তৈরি করি যেখানে প্রতিটি উপাদান $T[i][j]$ হলো $[i, i + 2^j - 1]$ ইন্টারভালে $A$-র মিনিমাম। স্পষ্টতই $0 \leq j \leq \lceil \log N \rceil$, এবং তাই স্পার্স টেবিলের আকার $O(N \log N)$। তুমি সহজেই $O(N \log N)$-এ এই টেবিল তৈরি করতে পারো, লক্ষ্য করে যে $T[i][j] = \min(T[i][j-1], T[i+2^{j-1}][j-1])$।
এই ডেটা স্ট্রাকচার ব্যবহার করে কীভাবে $O(1)$-এ RMQ কুয়েরির উত্তর দেওয়া যায়? ধরি প্রাপ্ত কুয়েরি হলো $[l, r]$, তাহলে উত্তর হলো $\min(T[l][\text{sz}], T[r-2^{\text{sz}}+1][\text{sz}])$, যেখানে $\text{sz}$ হলো সবচেয়ে বড় ঘাত যেন $2^{\text{sz}}$ রেঞ্জের দৈর্ঘ্য $r-l+1$-এর চেয়ে বড় না হয়। আসলে আমরা $[l, r]$ রেঞ্জটি নিয়ে $2^{\text{sz}}$ দৈর্ঘ্যের দুটি সেগমেন্ট দিয়ে ঢাকতে পারি - একটি $l$ থেকে শুরু এবং অন্যটি $r$-এ শেষ। এই সেগমেন্টগুলো ওভারল্যাপ করে, কিন্তু এটি আমাদের গণনায় বাধা দেয় না। প্রতিটি কুয়েরিতে $O(1)$ টাইম কমপ্লেক্সিটি অর্জনের জন্য, আমাদের $1$ থেকে $N$ পর্যন্ত সব সম্ভাব্য দৈর্ঘ্যের জন্য $\text{sz}$-এর মান জানতে হবে। কিন্তু এটি সহজেই প্রিকম্পিউট করা যায়।
এখন আমরা প্রিপ্রসেসিং-এর কমপ্লেক্সিটি $O(N)$-এ উন্নত করতে চাই।
আমরা $A$ অ্যারেটিকে $K = 0.5 \log N$ আকারের ব্লকে ভাগ করি যেখানে $\log$ হলো ২ ভিত্তিক লগারিদম। প্রতিটি ব্লকের জন্য মিনিমাম উপাদান গণনা করে $B$ অ্যারেতে সংরক্ষণ করি। $B$-এর আকার $\frac{N}{K}$। আমরা $B$ অ্যারে থেকে একটি স্পার্স টেবিল তৈরি করি। এর আকার এবং টাইম কমপ্লেক্সিটি হবে:
$$\frac{N}{K}\log\left(\frac{N}{K}\right) = \frac{2N}{\log(N)} \log\left(\frac{2N}{\log(N)}\right) =$$$$= \frac{2N}{\log(N)} \left(1 + \log\left(\frac{N}{\log(N)}\right)\right) \leq \frac{2N}{\log(N)} + 2N = O(N)$$এখন আমাদের শুধু শিখতে হবে কীভাবে প্রতিটি ব্লকের ভেতরে দ্রুত RMQ-র উত্তর দেওয়া যায়। আসলে যদি প্রাপ্ত RMQ $[l, r]$ হয় এবং $l$ ও $r$ ভিন্ন ব্লকে থাকে তাহলে উত্তর হলো নিচের তিনটি মানের মিনিমাম: $l$ থেকে শুরু হওয়া $l$-এর ব্লকের সাফিক্সের মিনিমাম, $r$-এ শেষ হওয়া $r$-এর ব্লকের প্রিফিক্সের মিনিমাম, এবং মাঝের ব্লকগুলোর মিনিমাম। মাঝের ব্লকগুলোর মিনিমাম স্পার্স টেবিল ব্যবহার করে $O(1)$-এ উত্তর দেওয়া যায়। তাই আমাদের শুধু ব্লকের ভেতরের RMQ গুলো বাকি আছে।
এখানে আমরা অ্যারের বিশেষ বৈশিষ্ট্য কাজে লাগাব। মনে কর যে অ্যারের মানগুলো - যেগুলো ট্রি-র উচ্চতার মান - সর্বদা এক দ্বারা পার্থক্য হয়। যদি আমরা একটি ব্লকের প্রথম উপাদান সরিয়ে ফেলি, এবং ব্লকের অন্য সব উপাদান থেকে এটি বিয়োগ করি, তাহলে প্রতিটি ব্লককে $K - 1$ দৈর্ঘ্যের $+1$ এবং $-1$ দিয়ে গঠিত একটি সিকোয়েন্স দ্বারা চিহ্নিত করা যায়। যেহেতু এই ব্লকগুলো এত ছোট, সম্ভাব্য সিকোয়েন্সের সংখ্যা খুব কম। সম্ভাব্য সিকোয়েন্সের সংখ্যা:
$$2^{K-1} = 2^{0.5 \log(N) - 1} = 0.5 \left(2^{\log(N)}\right)^{0.5} = 0.5 \sqrt{N}$$এভাবে ভিন্ন ব্লকের সংখ্যা $O(\sqrt{N})$, এবং তাই আমরা সব ভিন্ন ব্লকের ভেতরের RMQ-র ফলাফল $O(\sqrt{N} K^2) = O(\sqrt{N} \log^2(N)) = O(N)$ সময়ে প্রিকম্পিউট করতে পারি। ইমপ্লিমেন্টেশনের জন্য আমরা একটি ব্লককে $K-1$ দৈর্ঘ্যের একটি বিটমাস্ক দ্বারা চিহ্নিত করতে পারি (যেটি একটি স্ট্যান্ডার্ড int-এ ধরবে) এবং মিনিমামের ইনডেক্স $O(\sqrt{N} \log^2(N))$ আকারের $\text{block}[\text{mask}][l][r]$ অ্যারেতে সংরক্ষণ করতে পারি।
তাহলে আমরা শিখলাম কীভাবে প্রতিটি ব্লকের ভেতরের RMQ, সেই সাথে ব্লকগুলোর রেঞ্জের উপর RMQ প্রিকম্পিউট করতে হয়, সবই $O(N)$-এ।
এই প্রিকম্পিউটেশনগুলো দিয়ে আমরা প্রতিটি কুয়েরির উত্তর $O(1)$-এ দিতে পারি, সর্বোচ্চ চারটি প্রিকম্পিউটেড মান ব্যবহার করে: l ধারণকারী ব্লকের মিনিমাম, r ধারণকারী ব্লকের মিনিমাম, এবং তাদের মধ্যবর্তী ব্লকগুলোর ওভারল্যাপিং সেগমেন্টগুলোর দুটি মিনিমাম।
ইমপ্লিমেন্টেশন#
int n;
vector<vector<int>> adj;
int block_size, block_cnt;
vector<int> first_visit;
vector<int> euler_tour;
vector<int> height;
vector<int> log_2;
vector<vector<int>> st;
vector<vector<vector<int>>> blocks;
vector<int> block_mask;
void dfs(int v, int p, int h) {
first_visit[v] = euler_tour.size();
euler_tour.push_back(v);
height[v] = h;
for (int u : adj[v]) {
if (u == p)
continue;
dfs(u, v, h + 1);
euler_tour.push_back(v);
}
}
int min_by_h(int i, int j) {
return height[euler_tour[i]] < height[euler_tour[j]] ? i : j;
}
void precompute_lca(int root) {
// get euler tour & indices of first occurrences
first_visit.assign(n, -1);
height.assign(n, 0);
euler_tour.reserve(2 * n);
dfs(root, -1, 0);
// precompute all log values
int m = euler_tour.size();
log_2.reserve(m + 1);
log_2.push_back(-1);
for (int i = 1; i <= m; i++)
log_2.push_back(log_2[i / 2] + 1);
block_size = max(1, log_2[m] / 2);
block_cnt = (m + block_size - 1) / block_size;
// precompute minimum of each block and build sparse table
st.assign(block_cnt, vector<int>(log_2[block_cnt] + 1));
for (int i = 0, j = 0, b = 0; i < m; i++, j++) {
if (j == block_size)
j = 0, b++;
if (j == 0 || min_by_h(i, st[b][0]) == i)
st[b][0] = i;
}
for (int l = 1; l <= log_2[block_cnt]; l++) {
for (int i = 0; i < block_cnt; i++) {
int ni = i + (1 << (l - 1));
if (ni >= block_cnt)
st[i][l] = st[i][l-1];
else
st[i][l] = min_by_h(st[i][l-1], st[ni][l-1]);
}
}
// precompute mask for each block
block_mask.assign(block_cnt, 0);
for (int i = 0, j = 0, b = 0; i < m; i++, j++) {
if (j == block_size)
j = 0, b++;
if (j > 0 && (i >= m || min_by_h(i - 1, i) == i - 1))
block_mask[b] += 1 << (j - 1);
}
// precompute RMQ for each unique block
int possibilities = 1 << (block_size - 1);
blocks.resize(possibilities);
for (int b = 0; b < block_cnt; b++) {
int mask = block_mask[b];
if (!blocks[mask].empty())
continue;
blocks[mask].assign(block_size, vector<int>(block_size));
for (int l = 0; l < block_size; l++) {
blocks[mask][l][l] = l;
for (int r = l + 1; r < block_size; r++) {
blocks[mask][l][r] = blocks[mask][l][r - 1];
if (b * block_size + r < m)
blocks[mask][l][r] = min_by_h(b * block_size + blocks[mask][l][r],
b * block_size + r) - b * block_size;
}
}
}
}
int lca_in_block(int b, int l, int r) {
return blocks[block_mask[b]][l][r] + b * block_size;
}
int lca(int v, int u) {
int l = first_visit[v];
int r = first_visit[u];
if (l > r)
swap(l, r);
int bl = l / block_size;
int br = r / block_size;
if (bl == br)
return euler_tour[lca_in_block(bl, l % block_size, r % block_size)];
int ans1 = lca_in_block(bl, l % block_size, block_size - 1);
int ans2 = lca_in_block(br, 0, r % block_size);
int ans = min_by_h(ans1, ans2);
if (bl + 1 < br) {
int l = log_2[br - bl - 1];
int ans3 = st[bl+1][l];
int ans4 = st[br - (1 << l)][l];
ans = min_by_h(ans, min_by_h(ans3, ans4));
}
return euler_tour[ans];
}