নিকটতম বিন্দু জোড়া খুঁজে বের করা#
সমস্যার বিবরণ#
সমতলে $n$ টি বিন্দু দেওয়া আছে। প্রতিটি বিন্দু $p_i$ তার স্থানাঙ্ক $(x_i,y_i)$ দ্বারা সংজ্ঞায়িত। এদের মধ্যে এমন দুটি বিন্দু খুঁজে বের করতে হবে যাদের মধ্যে দূরত্ব সর্বনিম্ন:
$$ \min_{\scriptstyle i, j=0 \ldots n-1,\atop \scriptstyle i \neq j } \rho (p_i, p_j). $$আমরা সাধারণ ইউক্লিডীয় দূরত্ব নিই:
$$ \rho (p_i,p_j) = \sqrt{(x_i-x_j)^2 + (y_i-y_j)^2} .$$সরল অ্যালগরিদম — সব জোড়ার উপর ইটারেট করে প্রতিটির জন্য দূরত্ব গণনা — $O(n^2)$-এ কাজ করে।
$O(n \log n)$ সময়ে চলা অ্যালগরিদমটি নিচে বর্ণনা করা হয়েছে। এই অ্যালগরিদমটি ১৯৭৫ সালে Shamos ও Hoey প্রস্তাব করেছিলেন। (সূত্র: Kleinberg & Tardos-এর Algorithm Design-এর ৫ম অধ্যায়ের নোটস, আরও দেখুন এখানে) Preparata ও Shamos এও দেখিয়েছিলেন যে এই অ্যালগরিদমটি ডিসিশন ট্রি মডেলে অপটিমাল।
অ্যালগরিদম#
আমরা ডিভাইড অ্যান্ড কনকার অ্যালগরিদমের সাধারণ পরিকল্পনা অনুযায়ী একটি অ্যালগরিদম তৈরি করি: অ্যালগরিদমটি একটি রিকার্সিভ ফাংশন হিসেবে ডিজাইন করা হয়, যেখানে আমরা বিন্দুগুলোর একটি সেট পাস করি; এই রিকার্সিভ ফাংশন সেটটিকে অর্ধেক করে ভাগ করে, প্রতিটি অর্ধেকে নিজেকে রিকার্সিভভাবে কল করে, এবং তারপর উত্তরগুলো সংযুক্ত করার জন্য কিছু অপারেশন সম্পাদন করে। সংযুক্তকরণ অপারেশনে সেই ক্ষেত্রগুলো শনাক্ত করতে হয় যেখানে অপটিমাল সমাধানের একটি বিন্দু এক অর্ধেকে এবং অন্য বিন্দু অন্য অর্ধেকে পড়েছে (এই ক্ষেত্রে, প্রতিটি অর্ধেকের রিকার্সিভ কল এই জোড়া আলাদাভাবে শনাক্ত করতে পারে না)। প্রধান কঠিনতা, যেমনটা সবসময় ডিভাইড অ্যান্ড কনকার অ্যালগরিদমের ক্ষেত্রে হয়, মার্জিং পর্যায়ের দক্ষ ইমপ্লিমেন্টেশনে। যদি $n$ টি বিন্দুর একটি সেট রিকার্সিভ ফাংশনে পাস করা হয়, তাহলে মার্জ পর্যায় $O(n)$-এর বেশি কাজ করা উচিত না, তখন পুরো অ্যালগরিদমের অ্যাসিম্পটোটিকস $T(n)$ নিম্নলিখিত সমীকরণ থেকে পাওয়া যাবে:
$$T(n) = 2T(n/2) + O(n).$$এই সমীকরণের সমাধান, যেমনটা জানা আছে, $T(n) = O(n \log n).$
তাহলে, চলুন অ্যালগরিদম তৈরি করি। ভবিষ্যতে মার্জ পর্যায়ের দক্ষ ইমপ্লিমেন্টেশনে পৌঁছানোর জন্য, আমরা বিন্দু সেটটিকে তাদের $x$-স্থানাঙ্ক অনুযায়ী দুটি উপসেটে ভাগ করব: বস্তুত, আমরা একটি উল্লম্ব রেখা আঁকি যা বিন্দু সেটটিকে প্রায় সমান আকারের দুটি উপসেটে ভাগ করে। এমন ভাগ করা সুবিধাজনকভাবে নিম্নরূপে করা যায়: আমরা বিন্দুগুলোকে সংখ্যা জোড়া হিসেবে স্ট্যান্ডার্ড পদ্ধতিতে সাজাই, অর্থাৎ:
$$p_i < p_j \Longleftrightarrow (x_i < x_j) \lor \Big(\left(x_i = x_j\right) \wedge \left(y_i < y_j \right) \Big) $$তারপর সাজানোর পর মধ্যবর্তী বিন্দু $p_m (m = \lfloor n/2 \rfloor)$ নিই, এবং এর আগের সব বিন্দু ও $p_m$ নিজে প্রথম অর্ধেকে যায়, এবং এর পরের সব বিন্দু দ্বিতীয় অর্ধেকে:
$$A_1 = \{p_i \ | \ i = 0 \ldots m \}$$$$A_2 = \{p_i \ | \ i = m + 1 \ldots n-1 \}.$$এখন, $A_1$ ও $A_2$ সেটগুলোতে রিকার্সিভভাবে কল করে, আমরা প্রতিটি অর্ধেকের উত্তর $h_1$ ও $h_2$ পাব। এবং সেরাটি নিই: $h = \min(h_1, h_2)$।
এখন আমাদের একটি মার্জ পর্যায় করতে হবে, অর্থাৎ আমরা এমন বিন্দু জোড়া খুঁজতে চেষ্টা করি যাদের দূরত্ব $h$-এর চেয়ে কম এবং একটি বিন্দু $A_1$-এ ও অন্যটি $A_2$-তে। স্পষ্টতই, শুধুমাত্র সেই বিন্দুগুলো বিবেচনা করাই যথেষ্ট যারা উল্লম্ব রেখা থেকে $h$-এর চেয়ে কম দূরত্বে, অর্থাৎ এই পর্যায়ে বিবেচিত বিন্দুদের সেট $B$ হলো:
$$B = \{ p_i\ | \ | x_i - x_m\ | < h \}.$$$B$ সেটের প্রতিটি বিন্দুর জন্য, আমরা $h$-এর চেয়ে কাছের বিন্দু খুঁজতে চেষ্টা করি। উদাহরণস্বরূপ, শুধু সেই বিন্দুগুলো বিবেচনা করাই যথেষ্ট যাদের $y$-স্থানাঙ্ক $h$-এর বেশি ভিন্ন নয়। তাছাড়া, যেসব বিন্দুর $y$-স্থানাঙ্ক বর্তমান বিন্দুর $y$-স্থানাঙ্কের চেয়ে বেশি সেগুলো বিবেচনা করার কোনো মানে নেই। সুতরাং, প্রতিটি বিন্দু $p_i$-র জন্য আমরা বিবেচিত বিন্দুদের সেট $C(p_i)$ নিম্নরূপে সংজ্ঞায়িত করি:
$$C(p_i) = \{ p_j\ |\ p_j \in B,\ \ y_i - h < y_j \le y_i \}.$$যদি আমরা $B$ সেটের বিন্দুগুলো $y$-স্থানাঙ্ক অনুযায়ী সাজাই, তাহলে $C(p_i)$ খুঁজে পাওয়া খুব সহজ হবে: এগুলো হলো বিন্দু $p_i$-এর সামনে পরপর কয়েকটি বিন্দু।
সুতরাং, নতুন স্বরলিপিতে, মার্জিং পর্যায় এরকম দেখায়: $B$ সেট তৈরি করুন, এর বিন্দুগুলো $y$-স্থানাঙ্ক অনুযায়ী সাজান, তারপর প্রতিটি বিন্দু $p_i \in B$-এর জন্য $C(p_i)$-র সব বিন্দু $p_j$ বিবেচনা করুন, এবং প্রতিটি জোড়া $(p_i,p_j)$-এর দূরত্ব গণনা করে বর্তমান সর্বোত্তম দূরত্বের সাথে তুলনা করুন।
প্রথম দর্শনে, এটি এখনও একটি অ-অপটিমাল অ্যালগরিদম: মনে হয় $C(p_i)$ সেটগুলোর আকার $n$-এর ক্রমের হবে, এবং প্রয়োজনীয় অ্যাসিম্পটোটিকস কাজ করবে না। তবে, আশ্চর্যজনকভাবে, প্রমাণ করা যায় যে $C(p_i)$-র প্রতিটির আকার একটি $O(1)$ পরিমাণ, অর্থাৎ বিন্দুগুলো যাই হোক না কেন এটি কোনো ছোট ধ্রুবক অতিক্রম করে না। এই তথ্যের প্রমাণ পরবর্তী অংশে দেওয়া হয়েছে।
অবশেষে, আমরা সাজানোর দিকে মনোযোগ দিই, যা উপরের অ্যালগরিদমে রয়েছে: প্রথমত, $(x, y)$ জোড়া অনুযায়ী সাজানো, এবং দ্বিতীয়ত, $B$ সেটের উপাদানগুলো $y$ অনুযায়ী সাজানো। বস্তুত, রিকার্সিভ ফাংশনের ভেতরে এই দুটি সাজানোই বাদ দেওয়া যায় (অন্যথায় আমরা মার্জিং পর্যায়ের জন্য $O(n)$ অনুমানে পৌঁছাতে পারতাম না, এবং অ্যালগরিদমের সামগ্রিক অ্যাসিম্পটোটিকস $O(n \log^2 n)$ হতো)। প্রথম সাজানো থেকে মুক্তি পাওয়া সহজ — রিকার্সন শুরু করার আগেই এই সাজানো সম্পন্ন করাই যথেষ্ট: সর্বোপরি, রিকার্সনের ভেতরে উপাদানগুলো পরিবর্তিত হয় না, তাই আবার সাজানোর প্রয়োজন নেই। দ্বিতীয় সাজানো একটু কঠিন, আগে থেকে সাজানো কাজ করবে না। তবে, মার্জ সর্ট মনে করে দেখুন, যেটিও ডিভাইড অ্যান্ড কনকার নীতিতে কাজ করে, আমরা সহজেই এই সাজানো আমাদের রিকার্সনে এম্বেড করতে পারি। ধরি রিকার্সন, বিন্দুগুলোর একটি সেট নিয়ে (যেমনটা আমরা মনে করি, $(x, y)$ জোড়া অনুযায়ী সাজানো), একই সেট ফেরত দেয় কিন্তু $y$-স্থানাঙ্ক অনুযায়ী সাজানো। এটি করতে, শুধু ($O(n)$-এ) রিকার্সিভ কলের দুটি ফলাফল মার্জ করলেই হবে। এতে $y$-স্থানাঙ্ক অনুযায়ী সাজানো সেট পাওয়া যাবে।
অ্যাসিম্পটোটিকসের মূল্যায়ন#
উপরের অ্যালগরিদম আসলে $O(n \log n)$-এ সম্পাদিত হয় তা দেখাতে, আমাদের নিম্নলিখিত তথ্য প্রমাণ করতে হবে: $|C(p_i)| = O(1)$।
তাহলে, কোনো একটি বিন্দু $p_i$ বিবেচনা করি; স্মরণ করি যে $C(p_i)$ সেটটি হলো এমন বিন্দুদের সেট যাদের $y$-স্থানাঙ্ক $[y_i-h; y_i]$ খণ্ডে এবং তাছাড়া $x$ স্থানাঙ্ক বরাবর, বিন্দু $p_i$ নিজে ও $C(p_i)$ সেটের সব বিন্দু $2h$ প্রস্থের একটি ব্যান্ডে আছে। অন্য কথায়, আমরা যে বিন্দুগুলো বিবেচনা করছি $p_i$ ও $C(p_i)$ একটি $2h \times h$ আয়তক্ষেত্রে অবস্থিত।
আমাদের কাজ হলো এই $2h \times h$ আয়তক্ষেত্রে সর্বাধিক কতগুলো বিন্দু থাকতে পারে তা অনুমান করা; এভাবে আমরা $C(p_i)$ সেটের সর্বাধিক আকার অনুমান করি। একই সাথে, মূল্যায়ন করার সময়, আমাদের ভুলে গেলে চলবে না যে বিন্দু পুনরাবৃত্ত হতে পারে।
মনে রাখুন $h$ দুটি রিকার্সিভ কলের ফলাফল থেকে পাওয়া — $A_1$ ও $A_2$ সেটে, এবং $A_1$-এ বিভাজন রেখার বামের বিন্দু ও আংশিকভাবে রেখার উপরের বিন্দু রয়েছে, $A_2$-তে বিভাজন রেখার অবশিষ্ট বিন্দু ও ডানের বিন্দু রয়েছে। $A_1$-এর যেকোনো জোড়া, এবং $A_2$-এর যেকোনো জোড়ার দূরত্ব $h$-এর কম হতে পারে না — অন্যথায় এটি রিকার্সিভ ফাংশনের ভুল কাজ বোঝাত।
$2h \times h$ আয়তক্ষেত্রে সর্বাধিক বিন্দুর সংখ্যা অনুমান করতে আমরা এটিকে দুটি $h \times h$ বর্গক্ষেত্রে ভাগ করি, প্রথম বর্গক্ষেত্রে $C(p_i) \cap A_1$-এর সব বিন্দু এবং দ্বিতীয়টিতে বাকিগুলো, অর্থাৎ $C(p_i) \cap A_2$। উপরের আলোচনা থেকে জানা যায় যে এই বর্গক্ষেত্রগুলোর প্রতিটিতে যেকোনো দুটি বিন্দুর দূরত্ব কমপক্ষে $h$।
আমরা দেখাই যে প্রতিটি বর্গক্ষেত্রে সর্বাধিক চারটি বিন্দু থাকতে পারে। উদাহরণস্বরূপ, এটি নিম্নরূপে করা যায়: বর্গক্ষেত্রটিকে $h/2$ বাহু বিশিষ্ট $4$ টি উপ-বর্গক্ষেত্রে ভাগ করুন। তখন এই উপ-বর্গক্ষেত্রগুলোর প্রতিটিতে একটির বেশি বিন্দু থাকতে পারে না (কারণ কর্ণও $h / \sqrt{2}$, যা $h$-এর চেয়ে কম)। অতএব, পুরো বর্গক্ষেত্রে $4$ টির বেশি বিন্দু থাকতে পারে না।
সুতরাং, আমরা প্রমাণ করলাম যে $2h \times h$ আয়তক্ষেত্রে $4 \cdot 2 = 8$ টির বেশি বিন্দু থাকতে পারে না, এবং তাই $C(p_i)$ সেটের আকার $7$ অতিক্রম করতে পারে না, যেমনটা প্রয়োজন ছিল।
ইমপ্লিমেন্টেশন#
আমরা একটি বিন্দু সংরক্ষণের জন্য একটি ডেটা স্ট্রাকচার (এর স্থানাঙ্ক ও একটি নম্বর) এবং দুই ধরনের সাজানোর জন্য প্রয়োজনীয় তুলনা অপারেটর প্রবর্তন করি:
struct pt {
int x, y, id;
};
struct cmp_x {
bool operator()(const pt & a, const pt & b) const {
return a.x < b.x || (a.x == b.x && a.y < b.y);
}
};
struct cmp_y {
bool operator()(const pt & a, const pt & b) const {
return a.y < b.y;
}
};
int n;
vector<pt> a;রিকার্সনের সুবিধাজনক ইমপ্লিমেন্টেশনের জন্য, আমরা একটি সহায়ক ফাংশন upd_ans() প্রবর্তন করি, যা দুটি বিন্দুর মধ্যে দূরত্ব গণনা করবে এবং এটি বর্তমান উত্তরের চেয়ে ভালো কি না পরীক্ষা করবে:
double mindist;
pair<int, int> best_pair;
void upd_ans(const pt & a, const pt & b) {
double dist = sqrt((a.x - b.x)*(a.x - b.x) + (a.y - b.y)*(a.y - b.y));
if (dist < mindist) {
mindist = dist;
best_pair = {a.id, b.id};
}
}সবশেষে, রিকার্সনের ইমপ্লিমেন্টেশন। ধরে নেওয়া হচ্ছে এটি কল করার আগে $a[]$ অ্যারে ইতিমধ্যে $x$-স্থানাঙ্ক অনুযায়ী সাজানো। রিকার্সনে আমরা শুধু দুটি পয়েন্টার $l, r$ পাস করি, যা নির্দেশ করে এটি $a[l \ldots r)$-এর জন্য উত্তর খুঁজবে। $r$ ও $l$-এর মধ্যে দূরত্ব খুব ছোট হলে, রিকার্সন থামাতে হবে, এবং নিকটতম জোড়া খুঁজতে ও $y$-স্থানাঙ্ক অনুযায়ী সাবঅ্যারে সাজাতে একটি সরল অ্যালগরিদম সম্পাদন করতে হবে।
রিকার্সিভ কল থেকে প্রাপ্ত দুটি বিন্দু সেটকে একটিতে ($y$-স্থানাঙ্ক অনুযায়ী সাজানো) মার্জ করতে, আমরা স্ট্যান্ডার্ড STL $merge()$ ফাংশন ব্যবহার করি, এবং একটি সহায়ক বাফার $t[]$ তৈরি করি (সব রিকার্সিভ কলের জন্য একটি)। (inplace_merge() ব্যবহার করা ব্যবহারিক নয় কারণ এটি সাধারণত লিনিয়ার সময়ে কাজ করে না।)
সবশেষে, $B$ সেটটি একই $t$ অ্যারেতে সংরক্ষিত।
vector<pt> t;
void rec(int l, int r) {
if (r - l <= 3) {
for (int i = l; i < r; ++i) {
for (int j = i + 1; j < r; ++j) {
upd_ans(a[i], a[j]);
}
}
sort(a.begin() + l, a.begin() + r, cmp_y());
return;
}
int m = (l + r) >> 1;
int midx = a[m].x;
rec(l, m);
rec(m, r);
merge(a.begin() + l, a.begin() + m, a.begin() + m, a.begin() + r, t.begin(), cmp_y());
copy(t.begin(), t.begin() + r - l, a.begin() + l);
int tsz = 0;
for (int i = l; i < r; ++i) {
if (abs(a[i].x - midx) < mindist) {
for (int j = tsz - 1; j >= 0 && a[i].y - t[j].y < mindist; --j)
upd_ans(a[i], t[j]);
t[tsz++] = a[i];
}
}
}প্রসঙ্গত, যদি সব স্থানাঙ্ক পূর্ণসংখ্যা হয়, তাহলে রিকার্সনের সময়ে ভগ্নাংশ মানে না গিয়ে $mindist$-এ সর্বনিম্ন দূরত্বের বর্গ সংরক্ষণ করা যায়।
মূল প্রোগ্রামে, রিকার্সন নিম্নরূপে কল করতে হবে:
t.resize(n);
sort(a.begin(), a.end(), cmp_x());
mindist = 1E20;
rec(0, n);লিনিয়ার টাইম র্যান্ডমাইজড অ্যালগরিদম#
লিনিয়ার প্রত্যাশিত সময়ের একটি র্যান্ডমাইজড অ্যালগরিদম#
একটি বিকল্প পদ্ধতি, মূলত ১৯৭৬ সালে Rabin প্রস্তাব করেছিলেন, একটি অত্যন্ত সরল ধারণা থেকে উদ্ভূত হয়ে হিউরিস্টিকভাবে রানটাইম উন্নত করে: আমরা সমতলকে $d \times d$ বর্গক্ষেত্রের একটি গ্রিডে ভাগ করতে পারি, তখন শুধুমাত্র একই-ব্লক বা পাশের-ব্লকের বিন্দুদের মধ্যে দূরত্ব পরীক্ষা করতে হবে (যদি না সব বর্গ একে অপর থেকে বিচ্ছিন্ন হয়, কিন্তু আমরা ডিজাইনের মাধ্যমে এটি এড়াব), কারণ অন্য যেকোনো জোড়ার দূরত্ব একই বর্গের দুটি বিন্দুর চেয়ে বেশি।
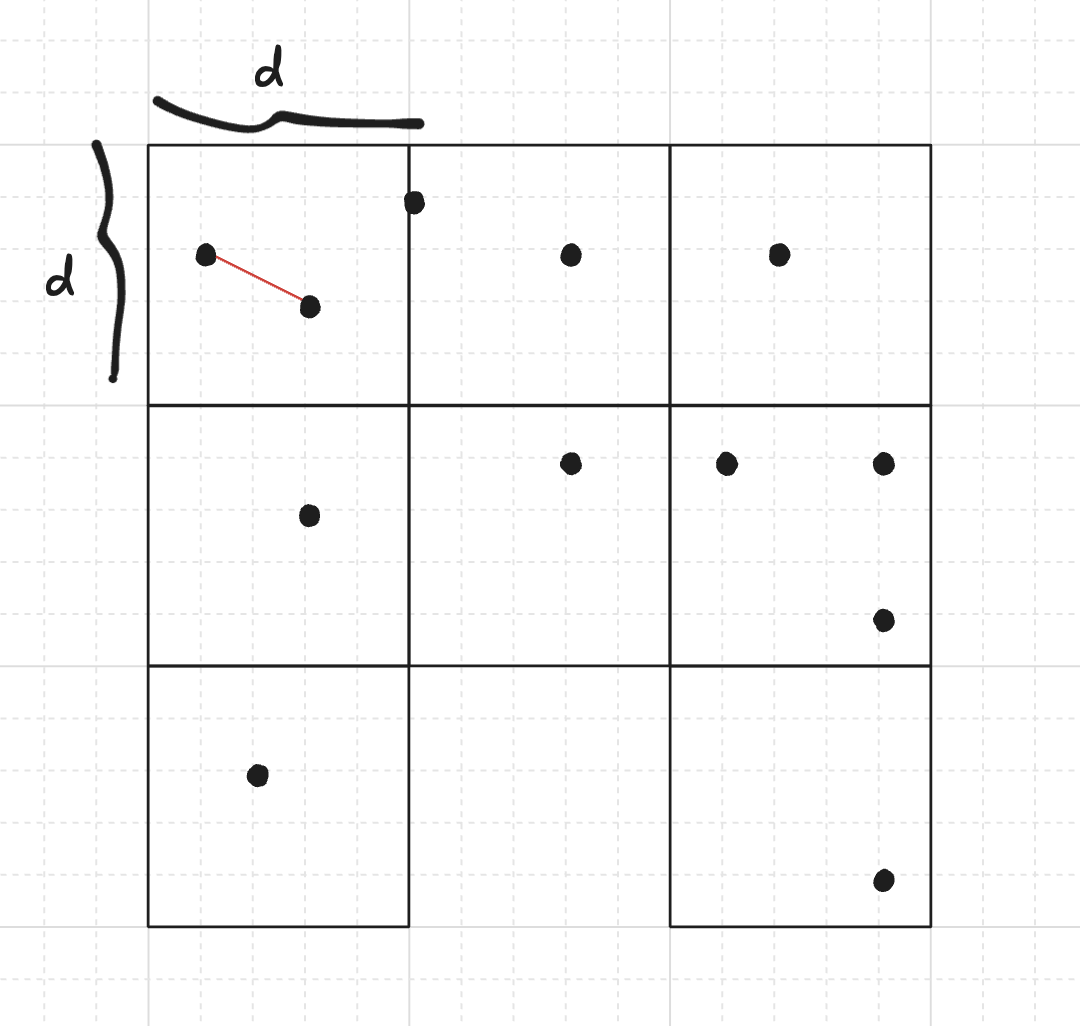
আমরা শুধুমাত্র কমপক্ষে একটি বিন্দু ধারণকারী বর্গক্ষেত্রগুলো বিবেচনা করব। $n_1, n_2, \dots, n_k$ দিয়ে $k$ টি অবশিষ্ট বর্গক্ষেত্রের প্রতিটিতে বিন্দু সংখ্যা বোঝাই। ধরে নিচ্ছি কমপক্ষে দুটি বিন্দু একই বা পাশের বর্গক্ষেত্রে আছে, এবং কোনো ডুপ্লিকেট বিন্দু নেই, টাইম কমপ্লেক্সিটি হলো $\Theta\!\left(\sum\limits_{i=1}^k n_i^2\right)$। আমরা হ্যাশ টেবিল ব্যবহার করে প্রত্যাশিত লিনিয়ার সময়ে ডুপ্লিকেট বিন্দু খুঁজতে পারি, এবং হ্যাঁ হলে উত্তর হলো সেই জোড়া।
প্রমাণ
এখন আমাদের ঠিক করতে হবে $d$ কীভাবে সেট করলে $\Theta\!\left(\sum\limits_{i=1}^k n_i^2\right)$ সর্বনিম্ন হয়।
d নির্বাচন#
আমাদের $d$ কে সর্বনিম্ন দূরত্ব $d$-এর একটি আনুমানিক মান হতে হবে। Richard Lipton প্রস্তাব করেছিলেন র্যান্ডমভাবে $n$ টি দূরত্ব স্যাম্পল করে তাদের মধ্যে ক্ষুদ্রতমটিকে $d$-এর আনুমানিক মান হিসেবে নেওয়ার। আমরা এখন প্রমাণ করি যে অ্যালগরিদমের প্রত্যাশিত রানিং টাইম লিনিয়ার।
প্রমাণ
$$\frac{\lambda(x) \, n / 32}{n^2 / 2} = \frac{\lambda(x)/16}{n}$$
তাই $n$ রাউন্ডে কমপক্ষে একটি এমন জোড়া নির্বাচিত হওয়ার (এবং তাই ছোট $d$ পাওয়ার) সম্ভাবনা হলো
$$1 - \left(1 - \frac{\lambda(x)/16}{n}\right)^n \ge 1 - e^{-\lambda(x)/16}$$
(আমরা ব্যবহার করেছি যে $(1 + x)^n \le e^{xn}$ যেকোনো বাস্তব সংখ্যা $x$-এর জন্য, দেখুন [বার্নোলি অসমতা](https://en.wikipedia.org/wiki/Bernoulli%27s_inequality#Related_inequalities))। <br> লক্ষ্য করুন $\lambda(x)$ বাড়ার সাথে সাথে এটি সূচকীয়ভাবে $1$-এর দিকে যায়। এটি ইঙ্গিত করে যে খারাপভাবে নির্বাচিত $d$-এর জন্য $\lambda$ ছোট হবে।
আমরা দেখিয়েছি যে $\Pr(d \le x) \ge 1 - e^{-\lambda(x)/16}$, বা সমতুল্যভাবে, $\Pr(d \ge x) \le e^{-\lambda(x)/16}$। $\Pr(\lambda(d) \ge \text{something})$ জানতে হবে যাতে এর প্রত্যাশিত মান অনুমান করা যায়। আমরা লক্ষ্য করি $\lambda(d) \ge \lambda(x) \iff d \ge x$। এটি কারণ বর্গক্ষেত্র ছোট করলে শুধু প্রতিটি বর্গক্ষেত্রে বিন্দু সংখ্যা কমে (বিন্দুগুলো অন্য বর্গক্ষেত্রে ভাগ হয়ে যায়), এবং এটি বর্গের যোগফল কমাতে থাকে। অতএব,
$$\Pr(\lambda(d) \ge \lambda(x)) = \Pr(d \ge x) \le e^{-\lambda(x)/16} \implies \Pr(\lambda(d) \ge t) \le e^{-t/16} \implies \mathbb{E}[\lambda(d)] \le \int_{0}^{+\infty} e^{-t/16} \, \mathrm{d}t = 16$$
(আমরা ব্যবহার করেছি যে $E[X] = \int_0^{+\infty} \Pr(X \ge x) \, \mathrm{d}x$, দেখুন [Stackexchange proof](https://math.stackexchange.com/a/1690829))।
সবশেষে, $\mathbb{E}[C(d)] = \mathbb{E}[\lambda(d) \, n] \le 16n$, এবং প্রত্যাশিত রানিং টাইম $O(n)$, যুক্তিসঙ্গত কনস্ট্যান্ট ফ্যাক্টর সহ। $\quad \blacksquare$
অ্যালগরিদমের ইমপ্লিমেন্টেশন#
এই অ্যালগরিদমের সুবিধা হলো এটি ইমপ্লিমেন্ট করা সরল, কিন্তু বাস্তবে ভালো পারফরম্যান্স দেয়। আমরা প্রথমে $n$ টি দূরত্ব স্যাম্পল করি এবং $d$ কে দূরত্বগুলোর সর্বনিম্ন হিসেবে সেট করি। তারপর আমরা ২D স্থানাঙ্ক থেকে বিন্দুদের ভেক্টরে একটি হ্যাশ টেবিল ব্যবহার করে বিন্দুগুলো “ব্লকে” ইনসার্ট করি। সবশেষে, একই-ব্লক ও পার্শ্ববর্তী-ব্লক জোড়াগুলোর মধ্যে দূরত্ব গণনা করি। হ্যাশ টেবিল অপারেশনের $O(1)$ প্রত্যাশিত সময় খরচ হয়, এবং তাই আমাদের অ্যালগরিদম বর্ধিত কনস্ট্যান্ট সহ $O(n)$ প্রত্যাশিত সময় খরচ বজায় রাখে।
Library Checker-এ এই সাবমিশনটি দেখুন।
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
struct pt {
ll x, y;
pt() {}
pt(ll x_, ll y_) : x(x_), y(y_) {}
void read() {
cin >> x >> y;
}
};
bool operator==(const pt& a, const pt& b) {
return a.x == b.x and a.y == b.y;
}
struct CustomHashPoint {
size_t operator()(const pt& p) const {
static const uint64_t C = chrono::steady_clock::now().time_since_epoch().count();
return C ^ ((p.x << 32) ^ p.y);
}
};
ll dist2(pt a, pt b) {
ll dx = a.x - b.x;
ll dy = a.y - b.y;
return dx*dx + dy*dy;
}
pair<int,int> closest_pair_of_points(vector<pt> P) {
int n = int(P.size());
assert(n >= 2);
// if there is a duplicated point, we have the solution
unordered_map<pt,int,CustomHashPoint> previous;
for (int i = 0; i < int(P.size()); ++i) {
auto it = previous.find(P[i]);
if (it != previous.end()) {
return {it->second, i};
}
previous[P[i]] = i;
}
unordered_map<pt,vector<int>,CustomHashPoint> grid;
grid.reserve(n);
mt19937 rd(chrono::system_clock::now().time_since_epoch().count());
uniform_int_distribution<int> dis(0, n-1);
ll d2 = dist2(P[0], P[1]);
pair<int,int> closest = {0, 1};
auto candidate_closest = [&](int i, int j) -> void {
ll ab2 = dist2(P[i], P[j]);
if (ab2 < d2) {
d2 = ab2;
closest = {i, j};
}
};
for (int i = 0; i < n; ++i) {
int j = dis(rd);
int k = dis(rd);
while (j == k) k = dis(rd);
candidate_closest(j, k);
}
ll d = ll( sqrt(ld(d2)) + 1 );
for (int i = 0; i < n; ++i) {
grid[{P[i].x/d, P[i].y/d}].push_back(i);
}
// same block
for (const auto& it : grid) {
int k = int(it.second.size());
for (int i = 0; i < k; ++i) {
for (int j = i+1; j < k; ++j) {
candidate_closest(it.second[i], it.second[j]);
}
}
}
// adjacent blocks
for (const auto& it : grid) {
auto coord = it.first;
for (int dx = 0; dx <= 1; ++dx) {
for (int dy = -1; dy <= 1; ++dy) {
if (dx == 0 and dy == 0) continue;
pt neighbour = pt(
coord.x + dx,
coord.y + dy
);
for (int i : it.second) {
if (not grid.count(neighbour)) continue;
for (int j : grid.at(neighbour)) {
candidate_closest(i, j);
}
}
}
}
}
return closest;
}একটি বিকল্প র্যান্ডমাইজড লিনিয়ার প্রত্যাশিত সময়ের অ্যালগরিদম#
এখন আমরা একটি ভিন্ন র্যান্ডমাইজড অ্যালগরিদম পরিচয় করাই যেটি কম ব্যবহারিক কিন্তু এটি যে প্রত্যাশিত লিনিয়ার সময়ে চলে তা দেখানো খুব সহজ।
- $n$ টি বিন্দু র্যান্ডমভাবে পারমিউট করুন
- $\delta := \operatorname{dist}(p_1, p_2)$ নিন
- সমতলকে $\delta/2$ বাহুর বর্গক্ষেত্রে ভাগ করুন
- $i = 1,2,\dots,n$-এর জন্য:
- $p_i$-এর সাথে সম্পর্কিত বর্গক্ষেত্র নিন
- বর্গক্ষেত্রের গ্রিডে আমাদের বর্গক্ষেত্র থেকে দুই ধাপের মধ্যে $25$ টি বর্গক্ষেত্রের উপর ইটারেট করুন
- যদি সেই বর্গক্ষেত্রগুলোতে কোনো $p_j$ থাকে যেন $\operatorname{dist}(p_j, p_i) < \delta$, তাহলে
- $\delta := \operatorname{dist}(p_j, p_i)$ দিয়ে ভাগ ও বর্গক্ষেত্র পুনর্গণনা করুন
- $p_1, \dots, p_i$ বিন্দুগুলো সংশ্লিষ্ট বর্গক্ষেত্রে সংরক্ষণ করুন
- অন্যথায়, $p_i$ কে সংশ্লিষ্ট বর্গক্ষেত্রে সংরক্ষণ করুন
- $\delta$ আউটপুট করুন
সঠিকতা এই তথ্য থেকে আসে যে যেকোনো মুহূর্তে আমাদের ইতিমধ্যে $\delta$ দূরত্বের কোনো জোড়া আছে, তাই আমরা শুধু $\delta$-র চেয়ে ছোট দূরত্বের নতুন জোড়া খুঁজি। যেহেতু প্রতিটি বর্গক্ষেত্রের বাহু $\delta/2$, একটি প্রার্থী জোড়া সর্বাধিক $2$ বর্গ দূরত্বে হতে পারে, তাই একটি প্রদত্ত বিন্দুর জন্য আমরা চারপাশের $25$ টি বর্গক্ষেত্রে প্রার্থী পরীক্ষা করি। আরও দূরের বর্গক্ষেত্রের কোনো বিন্দু সর্বদা $\delta$-র চেয়ে বেশি দূরত্ব দেবে।
এই অ্যালগরিদমটি দেখতে ধীর মনে হলেও, যেহেতু সবকিছু একাধিকবার পুনর্গণনা হয়, আমরা দেখাতে পারি মোট প্রত্যাশিত খরচ লিনিয়ার।
প্রমাণ
আমরা তাই দেখতে পাই যে প্রত্যাশিত খরচ হলো
$$O\!\left(n + \sum_{i=1}^{n} i \Pr(X_i = 1)\right) \le O\!\left(n + \sum_{i=1}^{n} i \frac{2}{i}\right) = O(3n) = O(n) \quad \quad \blacksquare$$
সাধারণীকরণ: সর্বনিম্ন পরিসীমা বিশিষ্ট ত্রিভুজ খুঁজে বের করা#
উপরে বর্ণিত অ্যালগরিদমটি আকর্ষণীয়ভাবে এই সমস্যায় সাধারণীকরণ করা যায়: প্রদত্ত বিন্দু সেট থেকে তিনটি ভিন্ন বিন্দু বেছে নিন যাতে তাদের জোড়াওয়ারি দূরত্বের যোগফল সর্বনিম্ন হয়।
বস্তুত, এই সমস্যা সমাধান করতে অ্যালগরিদম একই থাকে: আমরা ক্ষেত্রটিকে উল্লম্ব রেখা দিয়ে দুই ভাগে ভাগ করি, উভয় অর্ধেকে রিকার্সিভভাবে সমাধান কল করি, পাওয়া পরিসীমাগুলো থেকে সর্বনিম্ন $minper$ বেছে নিই, $minper / 2$ পুরুত্বের একটি ব্যান্ড তৈরি করি, এবং সব ত্রিভুজের উপর ইটারেট করি যারা উত্তর উন্নত করতে পারে। (লক্ষ্য করুন পরিসীমা $\le minper$ বিশিষ্ট ত্রিভুজের দীর্ঘতম বাহু $\le minper / 2$।)
অনুশীলন সমস্যা#
- UVA 10245 “The Closest Pair Problem” [কঠিনতা: সহজ]
- SPOJ #8725 CLOPPAIR “Closest Point Pair” [কঠিনতা: সহজ]
- CODEFORCES Team Olympiad Saratov - 2011 “Minimum amount” [কঠিনতা: মাঝারি]
- Google CodeJam 2009 Final “Min Perimeter” [কঠিনতা: মাঝারি]
- SPOJ #7029 CLOSEST “Closest Triple” [কঠিনতা: মাঝারি]
- TIMUS 1514 National Park [কঠিনতা: মাঝারি]