ছেদকারী রেখাংশের জোড়া খোঁজা#
সমতলে $n$টি রেখাংশ দেওয়া আছে। এদের মধ্যে অন্তত দুটি পরস্পরকে ছেদ করে কি না তা পরীক্ষা করতে হবে। যদি উত্তর হ্যাঁ হয়, তাহলে ছেদকারী রেখাংশের এই জোড়াটি প্রিন্ট করতে হবে; একাধিক উত্তরের মধ্যে যেকোনো একটি বেছে নিলেই যথেষ্ট।
সরল সমাধান অ্যালগরিদম হলো সব জোড়া রেখাংশের উপর $O(n^2)$-তে ইটারেট করা এবং প্রতিটি জোড়ার জন্য তারা ছেদ করে কি না তা পরীক্ষা করা। এই আর্টিকেলে $O(n \log n)$ রানটাইমের একটি অ্যালগরিদম বর্ণনা করা হয়েছে, যা সুইপ লাইন অ্যালগরিদমের উপর ভিত্তি করে।
অ্যালগরিদম#
চলুন মনে মনে একটি উল্লম্ব সরলরেখা $x = -\infty$ আঁকি এবং এই সরলরেখাটিকে ডানদিকে সরাতে শুরু করি। এটি সরানোর সময়, এই সরলরেখাটি রেখাংশগুলোর সাথে দেখা করবে, এবং প্রতিটি মুহূর্তে একটি রেখাংশ আমাদের সরলরেখার সাথে ছেদ করলে তা ঠিক একটি বিন্দুতে ছেদ করে (আমরা ধরে নেব যে কোনো উল্লম্ব রেখাংশ নেই)।
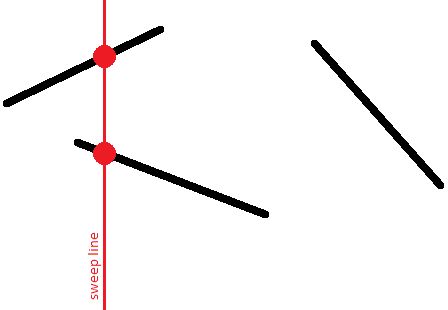
এইভাবে, প্রতিটি রেখাংশের জন্য, কোনো একটি সময়ে তার বিন্দু সুইপ লাইনে দেখা যাবে, তারপর সরলরেখাটি সরানোর সাথে সাথে এই বিন্দুটি সরে যাবে, এবং অবশেষে, কোনো একটি সময়ে, রেখাংশটি সরলরেখা থেকে অদৃশ্য হয়ে যাবে।
আমরা উল্লম্ব বরাবর রেখাংশগুলোর আপেক্ষিক ক্রমে আগ্রহী। অর্থাৎ, আমরা একটি প্রদত্ত সময়ে সুইপ লাইনকে ছেদ করা রেখাংশগুলোর একটি তালিকা সংরক্ষণ করব, যেখানে রেখাংশগুলো সুইপ লাইনে তাদের $y$-স্থানাঙ্ক অনুসারে সর্ট করা থাকবে।
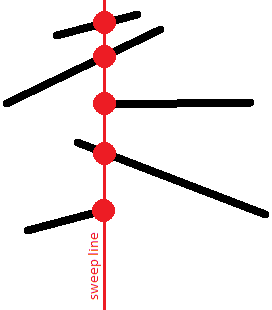
এই ক্রমটি আকর্ষণীয় কারণ ছেদকারী রেখাংশগুলোর অন্তত একটি সময়ে একই $y$-স্থানাঙ্ক থাকবে:
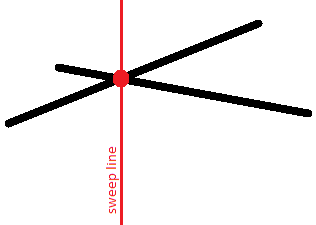
আমরা মূল বক্তব্যগুলো প্রণয়ন করি:
- একটি ছেদকারী জোড়া খুঁজতে, সুইপ লাইনের প্রতিটি নির্দিষ্ট অবস্থানে শুধুমাত্র পাশাপাশি রেখাংশগুলো বিবেচনা করাই যথেষ্ট।
- সুইপ লাইনটিকে সব সম্ভাব্য বাস্তব অবস্থানে ($-\infty \ldots +\infty$) বিবেচনা করার প্রয়োজন নেই, শুধুমাত্র সেই অবস্থানগুলোতে যেখানে নতুন রেখাংশ আবির্ভূত হয় বা পুরানোগুলো অদৃশ্য হয় সেখানেই যথেষ্ট। অন্য কথায়, রেখাংশের প্রান্তবিন্দুগুলোর ভুজের সমান অবস্থানগুলোতেই সীমাবদ্ধ থাকাই যথেষ্ট।
- যখন একটি নতুন রেখাংশ আবির্ভূত হয়, তখন পূর্ববর্তী সুইপ লাইনের জন্য প্রাপ্ত তালিকায় উপযুক্ত স্থানে এটি ইনসার্ট করাই যথেষ্ট। আমাদের শুধু যোগ করা রেখাংশটির সাথে তালিকায় তার ঠিক উপরে এবং নিচের প্রতিবেশীদের ছেদ পরীক্ষা করতে হবে।
- যদি রেখাংশটি অদৃশ্য হয়, তাহলে বর্তমান তালিকা থেকে এটি রিমুভ করাই যথেষ্ট। এরপর, তালিকায় উপরের এবং নিচের প্রতিবেশীদের ছেদ পরীক্ষা করা প্রয়োজন।
- তালিকায় রেখাংশের ক্রমের অন্য কোনো পরিবর্তন, উপরে বর্ণিতগুলো ছাড়া, নেই। অন্য কোনো ছেদ পরীক্ষার প্রয়োজন নেই।
এই বক্তব্যগুলোর সত্যতা বুঝতে, নিম্নলিখিত মন্তব্যগুলো যথেষ্ট:
- দুটি বিচ্ছিন্ন রেখাংশ কখনো তাদের আপেক্ষিক ক্রম পরিবর্তন করে না।
প্রকৃতপক্ষে, যদি একটি রেখাংশ প্রথমে অন্যটির চেয়ে উপরে থাকে, এবং পরে নিচে হয়ে যায়, তাহলে এই দুটি মুহূর্তের মধ্যে এই দুটি রেখাংশের একটি ছেদ ছিল। - দুটি অ-ছেদকারী রেখাংশেরও একই $y$-স্থানাঙ্ক থাকতে পারে না।
- এ থেকে এটি অনুসরণ করে যে রেখাংশ আবির্ভাবের মুহূর্তে আমরা কিউতে এই রেখাংশের জন্য অবস্থান খুঁজে পেতে পারি, এবং কিউতে এই রেখাংশটি আর পুনর্বিন্যাস করতে হবে না: কিউতে অন্যান্য রেখাংশের সাপেক্ষে এর ক্রম পরিবর্তন হবে না।
- দুটি ছেদকারী রেখাংশ তাদের ছেদবিন্দুর মুহূর্তে কিউতে পরস্পরের প্রতিবেশী হবে।
- অতএব, ছেদকারী রেখাংশের জোড়া খুঁজে পেতে শুধুমাত্র সেই সব জোড়া রেখাংশের ছেদ পরীক্ষা করাই যথেষ্ট যারা সুইপ লাইন চলাকালে কোনো না কোনো সময় পরস্পরের প্রতিবেশী ছিল।
লক্ষ্য করা সহজ যে শুধুমাত্র যোগ করা রেখাংশটিকে তার উপরের এবং নিচের প্রতিবেশীদের সাথে পরীক্ষা করা, এবং রেখাংশ সরানোর সময় — তার উপরের এবং নিচের প্রতিবেশীদের (যারা সরানোর পরে পরস্পরের প্রতিবেশী হয়ে যাবে) পরীক্ষা করাই যথেষ্ট। - লক্ষণীয় যে সুইপ লাইনের একটি নির্দিষ্ট অবস্থানে, আমাদের প্রথমে সব রেখাংশ যোগ করতে হবে যারা এই x-স্থানাঙ্কে শুরু হয়, এবং তারপরই সব রেখাংশ সরাতে হবে যারা এখানে শেষ হয়।
এইভাবে, আমরা শীর্ষবিন্দুতে রেখাংশের ছেদ মিস করি না: অর্থাৎ এমন ক্ষেত্র যেখানে দুটি রেখাংশের একটি সাধারণ শীর্ষবিন্দু আছে। - লক্ষ্য করুন যে উল্লম্ব রেখাংশগুলো আসলে অ্যালগরিদমের সঠিকতাকে প্রভাবিত করে না।
এই রেখাংশগুলো এই বিষয়ে বিশিষ্ট যে তারা একই সময়ে আবির্ভূত এবং অদৃশ্য হয়। তবে, পূর্ববর্তী মন্তব্যের কারণে, আমরা জানি যে সব রেখাংশ প্রথমে কিউতে যোগ হবে, এবং তারপরই সরানো হবে। অতএব, যদি উল্লম্ব রেখাংশটি সেই মুহূর্তে খোলা অন্য কোনো রেখাংশের (উল্লম্ব সহ) সাথে ছেদ করে, এটি সনাক্ত করা হবে।
কিউতে উল্লম্ব রেখাংশগুলো কোথায় রাখতে হবে? একটি উল্লম্ব রেখাংশের একটি নির্দিষ্ট $y$-স্থানাঙ্ক নেই, এটি $y$-স্থানাঙ্ক বরাবর একটি সম্পূর্ণ রেখাংশ জুড়ে বিস্তৃত। তবে, এটি বুঝতে সহজ যে এই রেখাংশ থেকে যেকোনো স্থানাঙ্ক $y$-স্থানাঙ্ক হিসেবে নেওয়া যায়।
এইভাবে, সম্পূর্ণ অ্যালগরিদম রেখাংশের একটি জোড়ার ছেদের উপর $2n$-এর বেশি পরীক্ষা করবে না, এবং রেখাংশের কিউতে $O(n)$টি অপারেশন করবে (প্রতিটি রেখাংশ আবির্ভাব এবং অদৃশ্য হওয়ার সময় $O(1)$টি অপারেশন)।
অ্যালগরিদমের চূড়ান্ত অ্যাসিম্পটোটিক আচরণ তাই $O(n \log n)$।
ইমপ্লিমেন্টেশন#
আমরা বর্ণিত অ্যালগরিদমের পূর্ণ ইমপ্লিমেন্টেশন উপস্থাপন করছি:
const double EPS = 1E-9;
struct pt {
double x, y;
};
struct seg {
pt p, q;
int id;
double get_y(double x) const {
if (abs(p.x - q.x) < EPS)
return p.y;
return p.y + (q.y - p.y) * (x - p.x) / (q.x - p.x);
}
};
bool intersect1d(double l1, double r1, double l2, double r2) {
if (l1 > r1)
swap(l1, r1);
if (l2 > r2)
swap(l2, r2);
return max(l1, l2) <= min(r1, r2) + EPS;
}
int vec(const pt& a, const pt& b, const pt& c) {
double s = (b.x - a.x) * (c.y - a.y) - (b.y - a.y) * (c.x - a.x);
return abs(s) < EPS ? 0 : s > 0 ? +1 : -1;
}
bool intersect(const seg& a, const seg& b)
{
return intersect1d(a.p.x, a.q.x, b.p.x, b.q.x) &&
intersect1d(a.p.y, a.q.y, b.p.y, b.q.y) &&
vec(a.p, a.q, b.p) * vec(a.p, a.q, b.q) <= 0 &&
vec(b.p, b.q, a.p) * vec(b.p, b.q, a.q) <= 0;
}
bool operator<(const seg& a, const seg& b)
{
double x = max(min(a.p.x, a.q.x), min(b.p.x, b.q.x));
return a.get_y(x) < b.get_y(x) - EPS;
}
struct event {
double x;
int tp, id;
event() {}
event(double x, int tp, int id) : x(x), tp(tp), id(id) {}
bool operator<(const event& e) const {
if (abs(x - e.x) > EPS)
return x < e.x;
return tp > e.tp;
}
};
set<seg> s;
vector<set<seg>::iterator> where;
set<seg>::iterator prev(set<seg>::iterator it) {
return it == s.begin() ? s.end() : --it;
}
set<seg>::iterator next(set<seg>::iterator it) {
return ++it;
}
pair<int, int> solve(const vector<seg>& a) {
int n = (int)a.size();
vector<event> e;
for (int i = 0; i < n; ++i) {
e.push_back(event(min(a[i].p.x, a[i].q.x), +1, i));
e.push_back(event(max(a[i].p.x, a[i].q.x), -1, i));
}
sort(e.begin(), e.end());
s.clear();
where.resize(a.size());
for (size_t i = 0; i < e.size(); ++i) {
int id = e[i].id;
if (e[i].tp == +1) {
set<seg>::iterator nxt = s.lower_bound(a[id]), prv = prev(nxt);
if (nxt != s.end() && intersect(*nxt, a[id]))
return make_pair(nxt->id, id);
if (prv != s.end() && intersect(*prv, a[id]))
return make_pair(prv->id, id);
where[id] = s.insert(nxt, a[id]);
} else {
set<seg>::iterator nxt = next(where[id]), prv = prev(where[id]);
if (nxt != s.end() && prv != s.end() && intersect(*nxt, *prv))
return make_pair(prv->id, nxt->id);
s.erase(where[id]);
}
}
return make_pair(-1, -1);
}এখানে প্রধান ফাংশন হলো solve(), যা ছেদকারী রেখাংশ থাকলে তা রিটার্ন করে, অথবা $(-1, -1)$, যদি কোনো ছেদ না থাকে।
দুটি রেখাংশের ছেদ পরীক্ষা intersect () ফাংশন দ্বারা করা হয়, যা ত্রিভুজের দিকনির্দেশিত ক্ষেত্রফলের উপর ভিত্তি করে একটি অ্যালগরিদম ব্যবহার করে।
রেখাংশের কিউ হলো গ্লোবাল ভেরিয়েবল s, একটি set<event>। ইটারেটর যা কিউতে প্রতিটি রেখাংশের অবস্থান নির্দেশ করে (কিউ থেকে রেখাংশ সুবিধাজনকভাবে সরানোর জন্য) গ্লোবাল অ্যারে where-তে সংরক্ষিত থাকে।
দুটি সহায়ক ফাংশন prev() এবং next()-ও চালু করা হয়েছে, যা পূর্ববর্তী এবং পরবর্তী এলিমেন্টের ইটারেটর রিটার্ন করে (অথবা end(), যদি একটি না থাকে)।
ধ্রুবক EPS দুটি বাস্তব সংখ্যা তুলনা করার ত্রুটি নির্দেশ করে (এটি প্রধানত দুটি রেখাংশের ছেদ পরীক্ষা করার সময় ব্যবহৃত হয়)।